


Nós estamos totalmente cientes da NVIDIA e de sua inteligência artificial “meu ouro” que desencadeou uma grande onda de interesse recentemente. No centro de tudo estão as GPUs de IA H100 da Equipe Green, que são, na realidade, o dispositivo de hardware para IA mais buscado no momento, com todos almejando obter uma para suprir suas necessidades de IA.
A RTX 100 GPU da NVIDIA é o processador ideal para inteligência artificial neste momento, e todos desejam ter mais desses.
Este artigo não tem características de notícia, mas informa os leitores sobre a atual realidade da indústria de Inteligência Artificial bem como como as empresas estão investindo nas GPUs H100 para sua “sobrevivência”.
A AMD informa que os modelos MI400 da nova geração de aceleradores de Inteligência Artificial já estão em operação.
Resumo: Em 2022, tudo estava indo bem. No entanto, em novembro, a aplicação “ChatGPT” emergiu, ajudando a estabelecer o hype da Inteligência Artificial. Esta aplicação não é a fundadora do boom da IA, mas foi um catalisador para a corrida à IA generativa, liderada por Microsoft e Google.
Onde vem a NVIDIA? O pilar da Inteligência Artificial (IA) gerativa abrange treinamentos extensos de LMM (Modelo de Linguagem de Maquina) e as GPUs de IA NVIDIA são a chave para isso. A fim de evitar que as coisas fiquem chatas e sem divertimento, vamos evitar entrar em especificações técnicas e fatos. No entanto, se você quiser conhecer detalhes, vamos destacar cada versão de GPU AI da NVIDIA, desde os modelos Tesla.
Las tarjetas gráficas NVIDIA HPC/AI ofrecen un rendimiento óptimo para tareas de computación de alto rendimiento y aprendizaje automático.
| NVIDIA Gráficos de Tesla Cartão | NVIDIA H100 (SMX5) | NVIDIA H100 (PCIe) | NVIDIA A100 (SXM4) | NVIDIA A100 (PCIe4) | Tesla V100S (PCIe) | Tesla V100 (SXM2) | Tesla P100 (SXM2) | Tesla P100 (PCI-Express) |
Tesla M40 (PCI-Express) |
Tesla K40 (PCI-Express) |
|---|---|---|---|---|---|---|---|---|---|---|
| GPU | GH100 (Hopper) | GH100 (Hopper) | GA100 (Ampere) | GA100 (Ampere) | GV100 (Volta) | GV100 (Volta) | GP100 (Pascal) | GP100 (Pascal) | GM200 (Maxwell) | GK110 (Kepler) |
| Node do processo | 4nm | 4nm | 7nm | 7nm | 12nm | 12nm | 16nm | 16nm | 28nm | 28nm |
| Transistores | 80 bilhões | 80 bilhões | 54.2 Bilhão | 54.2 Bilhão | 21.1 Biologia | 21.1 Biologia | 15.3 Bilhão | 15.3 Bilhão | 8 Billion | 7.1 Billion |
| GPU Tamanho de morrer | 814 mm2 | 814 mm2 | 826mm2 | 826mm2 | 815mm2 | 815mm2 | 610 mm2 | 610 mm2 | 601 mm2 | 551 mm2 |
| SMs | 132 | 114 | 108 | 108 | 80 | 80 | 56 | 56 | 24. | 15 |
| TPCs | 66 | 57 | 54 | 54 | 40 | 40 | 28 | 28 | 24. | 15 |
| FP32 CUDA Cores por SM | 128 | 128 | 64 | 64 | 64 | 64 | 64 | 64 | 128 | 192 |
| FP64 CUDA Cores / SM | 128 | 128 | 32 | 32 | 32 | 32 | 32 | 32 | 4 | 64 |
| FP32 CUDA Núcleos | 16896 | 14592 | 69 | 69 | 5120 | 5120 | 3584 | 3584 | 3072 | 2880 |
| FP64 CUDA Núcleos | 16896 | 14592 | 3456 | 3456 | 2560 | 2560 | 1792 | 1792 | 96 | 960 |
| Núcleos de Tensor | 528 | 456 | 432 | 432 | 640 | 640 | N/A | N/A | N/A | N/A |
| Unidades de textura | 528 | 456 | 432 | 432 | 320 | 320 | 224 | 224 | 192 | 240 |
| Melhorar o relógio | TBD | TBD | 1410 MHz | 1410 MHz | 1601 MHz | 1530 MHz | 1480 MHz | 1329MHz | 1114 MHz | 875 MHz |
| TOPs (DNN/AI) | 3958 TOPs | 3200 TOPs | 1248 TOPs 2496 TOPs com Sparsity |
1248 TOPs 2496 TOPs com Sparsity |
130 TOPs | 125 TOPs | N/A | N/A | N/A | N/A |
| FP16 Compute | 1979 TFLOPs | 1600 TFLOPs | 312 TFLOPs 624 TFLOPs com Sparsity |
312 TFLOPs 624 TFLOPs com Sparsity |
32.8 TFLOPs | 30.4 TFLOPs | 21.2 TFLOPs | 18.7 TFLOPs | N/A | N/A |
| FP32 Compute | 67 TFLOPs | 800 TFLOPs | 156 TFLOPs (19.5 TFLOPs padrão) |
156 TFLOPs (19.5 TFLOPs padrão) |
16.4 TFLOPs | 15.7 TFLOPs | 10.6 TFLOPs | 10.0 TFLOPs | 6.8 TFLOPs | TFLOPs 5.04 |
| FP64 Compute | 34 TFLOPs | 48 TFLOPs | 19.5 TFLOPs (9,7 TFLOPs padrão) |
19.5 TFLOPs (9,7 TFLOPs padrão) |
8.2 TFLOPs | 7.80 TFLOPs | 5.30 TFLOPs | 4.7 TFLOPs | 0,2 TFLOPs | 1.68 TFLOPs |
| Interface de memória | HBM3 de 5120 bits | HBM2e de 5120 bits | 6144-bit HBM2e | 6144-bit HBM2e | HBM2 de 4096 bits | HBM2 de 4096 bits | HBM2 de 4096 bits | HBM2 de 4096 bits | 384 bits GDDR5 | 384 bits GDDR5 |
| Tamanho da memória | Até 80 GB HBM3 @ 3.0 Gbps | Até 80 GB HBM2e @ 2.0 Gbps | Até 40 GB HBM2 @ 1.6 TB/s Até 80 GB HBM2 @ 1,6 TB/s |
Até 40 GB HBM2 @ 1.6 TB/s Até 80 GB HBM2 @ 2.0 TB/s |
16 GB HBM2 @ 1134 GB/s | 16 GB HBM2 @ 900 GB/s | 16 GB HBM2 @ 732 GB/s | 16 GB HBM2 @ 732 GB/s 12 GB HBM2 @ 549 GB/s |
24 GB GDDR5 @ 288 GB/s | 12 GB GDDR5 @ 288 GB/s |
| Tamanho de cache L2 | 51200 KB | 51200 KB | 40960 KB | 40960 KB | 6144 KB | 6144 KB | 4096 KB | 4096 KB | 3072 KB | 1536 KB |
| TPI | 700W | 350W | 400W | 250W | 250W | 300W | 300W | 250W | 250W | 235W |
Ainda não há resposta para a pergunta: “Por que os H100s?” Mas estamos chegando lá. Os H100 da NVIDIA são a linha de produtos mais avançada da empresa, oferecendo alta capacidade de computação. Apesar do preço mais alto, as empresas costumam encomendar grandes lotes, e a prioridade é o “desempenho por watt”. Ainda assim, quando comparado com o A100, o H100 é mais vantajoso, pois oferece 3,5 vezes mais capacidade de inferência em 16 bits e 2,3 vezes mais desempenho de treinamento em 16 bits, tornando-se a escolha lógica.

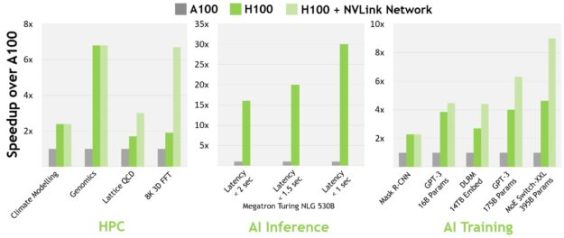
Espera-se que seja óbvia a superioridade da GPU H100. Vamos agora para o próximo tópico, por que existe escassez? Há vários motivos para isso, um deles é devido ao grande volume de H100 necessário para aprimorar um único programa. É impressionante que o modelo de inteligência artificial GPT-4 da OpenAI exigiu entre 10.000 e 25.000 GPUs A100 (naquele momento, os H100 ainda não haviam sido lançados).
As startups de IA modernas, como Inflection AI e CoreWeave, obtiveram enormes valores para H100s, totalizando bilhões em contas. Isso indica que é necessária uma grande quantidade de recursos para treinar um modelo AI relativamente básico, explicando a demanda significativa.

Se você questionar a abordagem da NVIDIA, pode-se dizer: “A NVIDIA poderia aumentar a produção para satisfazer a demanda.” Expressar essa ideia é muito mais fácil do que realmente executá-la. Ao contrário das GPUs de jogos, as GPUs NVIDIA AI requerem processos complexos, com a maior parte da fabricação designada ao taiwanês gigante TSMC. O TSMC é o fornecedor exclusivo da GPU AI da NVIDIA, supervisionando todos os passos do processo, desde a adquirir wafers à embalagens avançadas.
As GPUs H100 são baseadas no processamento 4N do TSMC, uma atualização renovada da família 5nm. Desde que a Apple anteriormente empregou o chipset biônico A15, NVIDIA se tornou o maior consumidor desta tecnologia, mas foi substituída pelo A16 Bionic. A fabricação de memória HBM é a etapa mais complexa, tendo como requisito equipamentos sofisticados, atualmente em uso por alguns fabricantes.

A HBM conta com SK Hynix, Micron e Samsung como seus fornecedores, mas o TSMC tem mantido seus provedores em segredo. Além disso, o TSMC tem problemas para manter sua capacidade CoWoS (Chip-on-Wafer-on-Substrate), que é necessária para a produção de H100s, o que resultou em um aumento dos backlogs de encomendas da NVIDIA para dezembro.
Quando as pessoas mencionam “escassez de GPU”, isso se refere a uma escassez de componentes na placa, e não ao próprio chip gráfico. A produção mundial é limitada, mas tentamos prever o que o mercado precisa e o que o mundo pode produzir.
O Vice-Presidente e Gerente-Geral da DGX da NVIDIA, Charlie Doyle, foi nomeado.
Nós omitimos muitos detalhes, mas focamos no objetivo de fornecer informações ao usuário médio sobre a situação. A escassez não deve diminuir e pode aumentar. A AMD fez uma mudança de cenário para solidificar sua presença no mercado de Inteligência Artificial.
DigiTimes informa que “TSMC está particularmente entusiasmada com a demanda para a próxima série Instinct MI300 da AMD, relatando que será equivalente a 50% da quantidade de chips embalados pela CoWoS da Nvidia”. Para alcançar essa meta, a AMD teria que oferecer aos fabricantes uma oferta extremamente atraente, dada a tendência de lucro da Team Green no passado.
Reinvocando nossa conversa, o H100 da NVIDIA GPUs está elevando o hype AI a patamares mais altos, o que explica o frenesi ao seu redor. Nós pretendíamos encerrar nosso bate-papo transmitindo aos leitores uma noção geral do cenário. Créditos a GPU Utilis por ter fornecido a ideia por trás deste trabalho; não deixe de conferir o relatório deles também.
Fontes de informação: GPU usada para aumentar a velocidade de processamento de informações